Table of Contents
1 - Objectifs
L'objectif de ce TP est de vous faire mettre en oeuvre une structure de données efficace pour les ensembles disjoints : la forêt. On se servira de cette structure pour faire de la segmentation d'image, c'est-à-dire une partition de l'image en zones d'intérêt.
Pour faciliter la visualisation, on utilisera la bibliothèque GTK (http://www.gtk.org) comme interface graphique. Elle permet de charger les images, de les afficher, d'avoir des boutons et sélecteur de paramètres, etc.
Pour vous faire gagner du temps, on vous donne une application de base union-find.c , qui charge une image et permet de choisir entre deux pixbufs pour la visualisation (l'image en entrée et l'image de sortie calculée).
Prenez d'abord le temps de bien comprendre le code écrit, le source est consultable là: union-find.c et est présent dans l'archive, le fichier Makefile est ci-dessous:
Pour l'exécuter, on pourra lui donner en paramètre un nom de fichier image (JPG, PNG, PGM, etc).
prompt$ make prompt$ ./union-find papillon-express.jpg
1.1 Quelques précisions utiles
GTK, et plus précisément GDK, voit les images sous forme de tableaux d'octets (type unsigned char ou guchar), appelé GdkPixbuf. Chaque pixel est en général codé sur 3 octets :
- le premier octet code l'intensité de rouge entre 0 (aucun) et 255 (rouge à fond)
- le deuxième octet code l'intensité de vert entre 0 (aucun) et 255 (vert à fond)
- le troisième octet code l'intensité de bleu entre 0 (aucun) et 255 (bleu à fond)
Dans l'image, le GdkPixbuf commence par stocker le pixel le plus en haut à gauche, puis stocke les pixels ligne par ligne. Les pixels d'une même ligne sont à la suite les uns des autres (donc tous les 3 octets). Pour passer d'une ligne à une autre, on ajoute rowstride octets au début de l'adresse du pixel de la ligne précédente.
On crée un type Pixel pour simplifier l'accès aux pixels. Le bout de code ci-dessous montre comment mettre la composante rouge de tous les pixels d'une image à fond.
1.2 Réaction à un clic sur un bouton et appel d'une fonction
On voit que les fonctions selectInput et selectOutput sont des fonctions "call-back" ou réaction qui sont appelés lors d'un événement précis. Elles reçoivent en paramètre un pointeur, qui est ici le pointeur vers la variable contexte. Celle-ci nous permet donc d'accéder aux données utiles pour faire la segmentation.
1.3 Segmentation d'image
L'objectif de la segmentation d'image est de réaliser une partition de l'image en régions d'intérêt, afin de simplifier son analyse postérieure, notamment pour la reconnaissance ou l'indexation. Une région est souvent définie comme un ensemble de points connexes du plan. Pour faire simple, il y a deux grandes familles de techniques:
- l'approche par homogénéité: on définit les régions comme des zones à peu près homogènes, i.e. de couleurs et intensités proches.
- l'approche par hétérogénéité: on définit les frontières entre régions comme des endroits où il y a de fortes variations de la couleur et/ou de l'intensité.
Evidemment, on fait souvent un mélange de ces deux approches duales. Ici, ce que vous allez faire relève des deux approches:
- l'approche par homogénéité: le seuillage regroupe zones claires ensembles et zones sombres ensemble (2 Seuillage de l'image) et l'extraction de composantes connexes en définit les régions (3 Découpage de l'image seuillée en composantes connexes). Souvent, on préférerait faire un K-means ou K-moyennes (http://fr.wikipedia.org/wiki/Algorithme_des_k-moyennes) plutôt qu'un seuillage en première phase.
- l'approche par hétérogénéité: la non-similitude découpe le graphe autour des hétérogénéité et l'extraction de composantes connexes qui suit bloque sur les frontières pour retrouver les régions (5 Connexité floue et découpage en composantes connexes floues).
2 Seuillage de l'image
On commence par faire un traitement très simple sur l'image, le seuillage par un niveau de gris T entre 0 et 255. Il s'agit tout simplement de transformer l'image donnée en entrée en une image noir et blanc telle que:
- soit g le niveau de gris d'un pixel p dans le pixbuf
input(obtenu par un appel de greyLevel). - si g est strictement plus petit que T, alors le pixel à la même position que p dans le pixbuf
outputest mis noir (appel de setGreyLevel avec 0) - sinon le pixel à la même position que p dans le pixbuf
outputest mis blanc (appel de setGreyLevel avec 255)
Créer donc un GtkScale et un bouton "Seuiller" et rajoutez les dans l'IHM pour que l'utilisateur puisse choisir son seuil et lancer le seuillage. L'image seuillée sera placée dans le pixbuf output du contexte.
N'oubliez pas de stocker le widget dans le contexte pour que vous puissiez accéder à la valeur choisie dans votre réaction seuillerImage. On utilisera la fonction gtk_range_get_value pour récupérer la valeur du widget. Cela donnera quelque chose du genre:
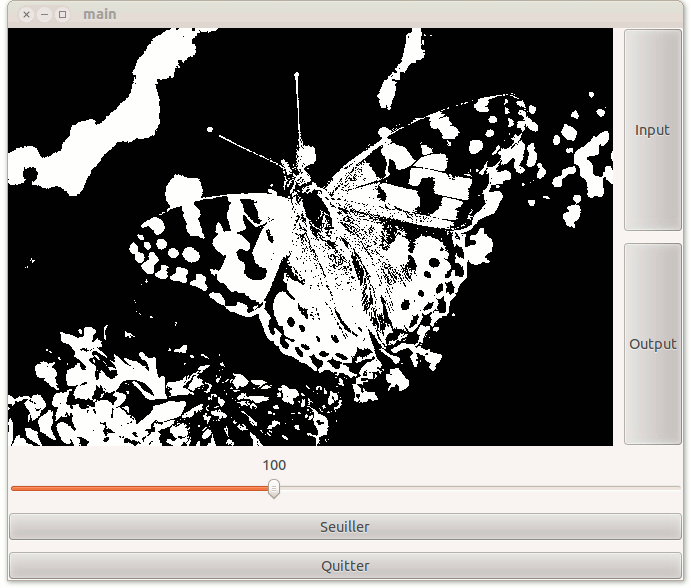
3 Découpage de l'image seuillée en composantes connexes
On va maintenant coder une structure Union-Find pour calculer les composantes connexes de l'image seuillée. A une image seuillée, on associe un graphe dont les sommets sont les pixels et les arêtes relient deux pixels qui se touchent si ils ont même valeur. On cherchera à extraire les composantes connexes de ce graphe, c'est-à-dire les parties où il existe un chemin entre pixels. Dans un premier temps, on code une structure Union-Find, dans un deuxième temps on l'utilisera sur l'image.
3.1 Présentation des structures Union-Find par forêt
Une présentation plus détaillée est à la fin de la Leçon 3 d'INFO601_cmi. Les forêts constituent la structure de données la plus efficace pour coder les problèmes utilisant les ensembles disjoints (i.e. \( S = \cup_i S_i \) et \( \forall i \neq j, S_i \cap S_j = \emptyset \)).
Chaque sous-ensemble est représenté par un arbre, dont les noeuds sont les objets appartenant à l'ensemble et la racine est le représentant de l'ensemble. Chaque noeud d'un arbre a donc un pointeur vers son parent. La racine pointe vers elle-même et est le représentant du sous-ensemble constitué de tous les noeuds de l'arbre. Les fonctions sur les ensembles disjoints sont mis en oeuvre ainsi:
- Un appel de
Créer-Ensemble(x)crée simplement un arbre a un seul noeudx(coûte \( \Theta(1) \)). - La fonction
Trouver(x)remonte d'un noeudxjusqu'à sa racine et retourne la racine, ce qui coûte \( \Theta(k) \) où k est la profondeur du noeud. - La fonction
Union(x,y)relie la racine dexà la racine dey, sixetyn'ont pas le même représentant (i.e. la même racine). Pour ce faire, il suffit donc de remonter à la racine de chaque arbre et de modifier un pointeur.
Telle quelle, cette implémentation n'est pas plus rapide que celle utilisant les listes chaînées. On applique deux heuristiques à cette structure de façon à la rendre la plus efficace possible.
- L' union par rang. On stocke dans chaque noeud un majorant de la hauteur de son sous-arbre appelé rang (qui vaut 1 lorsque l'arbre est réduit à un élément). Lorsqu'on réalise l'union, c'est la racine de moindre rang qui pointe vers la racine de rang supérieur. C'est seulement lorsque les deux racines ont même rang qu'on augmente le rang. Il est clair que cette opération ne rajoute pas de surcoût en temps.
- La compression de chemin. Dès que l'on utilise
Trouver, tous les noeuds traversés pour trouver la racine, sont modifiés de façon à ce que leur parent soit directement la racine. Il est clair que cette opération ne rajoute pas de surcoût en temps.
Ces heuristiques ont un effet très important sur la complexité amortie des opérations sur les ensembles disjoints. On a :
Théorème [Tarjan 1975]. Si on utilise les forêts d'ensembles disjoints avec les heuristiques d'union par rang et de compression de chemin, alors une séquence arbitraire de \( m \) opérations Créer-Ensemble, Trouver, Union prend un temps \( O(m
\alpha(n)) \), où \( \alpha(n) \) est une fonction qui croît extrêmement lentement ( \( n \le 4 \) dans tous les cas concevables).
- Note
- La preuve se fait en utilisant la méthode du potentiel.
3.2 Codage des structures Union-Find par forêt
La difficulté est de coder la notion abstraite d'Objet (ou d'Element) définie en cours. L'Objet stockera un pointeur vers le pixel associé, son rang et un pointeur vers son père. On aura exactement un Objet par Pixel. Nous procéderons ainsi:
On va créer autant d'Objet que de pixels. On les place dans un grand tableau d'Objet, indicés de 0 à width*height-1, dans l'ordre habituel. Au début, chaque Objet doit pointer sur le bon pixel, avoir rang 0, et son père c'est lui-même. Ecrivez donc la fonction creerEnsembles qui fait ce travail et retourne ce tableau d'Objet alloué dynamiquement. Son prototype sera:
- Note
- Cette fonction est délicate. Vérifiez bien que les champs
pixeletperesont remplis correctement. Au besoin, me demander.
Il faut ensuite créer les fonctions usuelles:
Vous créerez les deux versions de Union (avec ou sans Union par rang), et les deux versions de Trouver (avec ou sans compression de chemin).
3.3 Utilisation de cette structure pour le découpage en composantes connexes.
L'image seuillée est vue comme un graphe dont les sommets sont les pixels, et les arêtes relient deux pixels adjacents si ils ont la même valeur. Voilà le graphe (implicite) de la petite image binaire ci-dessous.

Image binaire | 
Son graphe de connexité induit. |
Créez maintenant un nouveau bouton "Composantes connexes" avec une réaction ComposantesConnexes. Elle réalisera l'algorithme ci-dessous:
0) elle travaillera directement sur le `pixbuf_output` du contexte, en supposant que l'on a déjà appelé `seuiller` dessus.
1) Objet* objets = CreerEnsembles( ... ); // elle commence par créer le tableau d'`Objet`.
2) Soit i = 0, le numero de l'objet courant
3a) Pour toute paire d'objets objets[i] et objets[i+1] adjacents horizontalement,
si ils ont même valeurs, on fait l'union.
3b) Pour toute paire d'objets objets[i] et objets[i+width] adjacents verticalement,
si ils ont même valeurs, on fait l'union.
4) On reparcourt tous les objets et on affecte une couleur aléatoire à tous les objets
qui sont des représentants
5) On reparcourt tous les objets et on leur affecte la couleur de leur représentant
6) on force le réaffichage pour voir le résultat.
Sur l'exemple précédent du papillon seuillée à 100, voilà ce que vous obtenez:
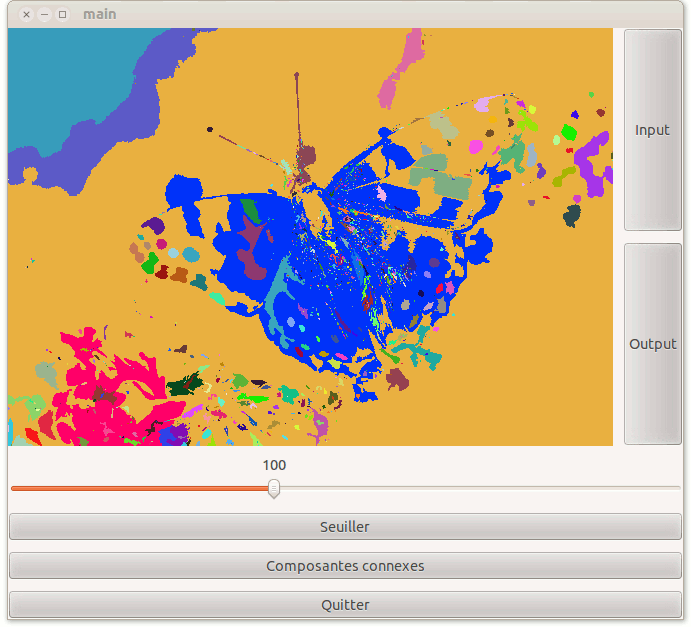
- Note
- Faites attention aux bords de l'image ! (bord droit pour les adjacences horizontales, bord bas pour les adjacences verticales).
3.4 Temps d'exécution de Union-Find.
On vérifiera que l'efficacité de la structure Union-Find est très dépendante des deux heuristiques d'optimisation. Pour mesurer le temps, on pourra utiliser à profit le bout de code suivant (Linux):
Il faudra modifier les deux lignes suivantes dans le Makefile:
CFLAGS=-g -Wall -Werror -pedantic -std=c11 -D_POSIX_C_SOURCE=199309 GTKLIBS:=$(shell pkg-config --libs gtk+-3.0) -lrt
Vous ferez un tableau où vous mesurerez les temps d'exécution avec plusieurs images de tailles différentes croisées avec les 4 algos Union-Find possible (Union-Find bête, Union-Find avec union par rang, Union-Find avec compression de chemins, Union-Find avec union par rang et compression de chemin). Vérifiez que le temps d'exécution est quasi-linéaire dans le dernier cas.
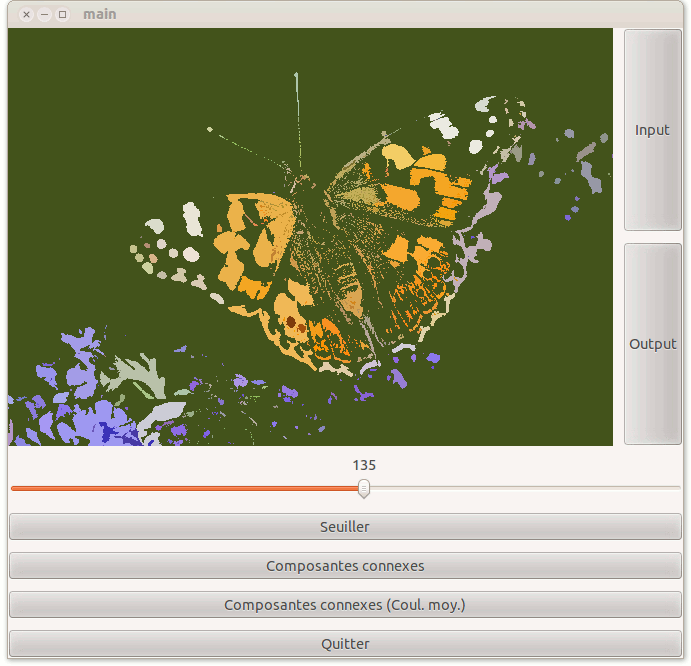
4 Affichage de la couleur moyenne pour chaque région
Pour faire plus "joli", plutôt que d'afficher une couleur aléatoire pour une région, on va afficher la couleur moyenne de tous les pixels de la même région. Pour nous, la couleur moyenne sera les moyennes respectives de chaque canal de couleur (ce qui est un peu faux du point de vue vision humaine). On adapte la fonction précédentes ComposantesConnexes dans sa deuxième partie. On se donne d'abord une structure pour stocker les moyennes de couleur:
Ensuite, les points 4), 5) et 6) de l'algorithme précédents sont remplacés par:
Cela vous donne sur l'exemple papillon un affichage similaire à ci-dessous:
5 Connexité floue et découpage en composantes connexes floues
Le seuillage est bien souvent trop limité. En général on utilise des techniques plus évoluées comme les K-means, la segmentation par minimisation d'une énergie, la segmentation supervisée, etc. Nous proposons ici une petite évolution de l'approche précédente, appelée par certains auteurs la connexité floue.
On utilise les définitions suivantes. Soit \( \rho(x,x') \) une fonction appelée similitude qui retourne un nombre >= 0 étant donné deux pixels adjacents x et x'. Plus \( \rho \) est proche de 0, plus les pixels x et x' sont similaires. On dit que deux pixels arbitraires x et y (pas forcément adjacents) sont \( \alpha \)-connexes (pour \( \alpha \ge 0 \)) si et seulement si il existe un chemin de pixels deux à deux adjacents entre x et y tels que chacun de ces pixels adjacents ont une similitude inférieure ou égale à \( \alpha \).
La relation d' \( \alpha \)-connexité est donc une généralisation de la connexité où deux pixels adjacents devaient être identiques (cf 2 Seuillage de l'image et 3 Découpage de l'image seuillée en composantes connexes). Maintenant, ils ont seulement besoin d'être similaire. En revanche, l'algorithme Union-Find fonctionnera toujours.
0) On travaillera directement sur le `pixbuf_output` du contexte, en supposant qu'on a copié l'`input` dessus avant.
1) Objet* objets = CreerEnsembles( ... ); // elle commence par créer le tableau d'`Objet`.
2) Soit i = 0, le numero de l'objet courant
3a) Pour toute paire d'objets objets[i] et objets[i+1] adjacents horizontalement,
si ils sont similaires, on fait l'union.
3b) Pour toute paire d'objets objets[i] et objets[i+width] adjacents verticalement,
si ils sont similaires, on fait l'union.
4) On calcule la couleur moyenne de chaque région que l'on donne au représentant.
5) On affecte à chaque pixel la couleur moyenne de son représentant.
6) on force le réaffichage pour voir le résultat.
On peut définir plein de fonctions "similitude". On va en créer une qui se base sur la représentation TSV des couleurs ou Teinte / Saturation / Valeur (http://fr.wikipedia.org/wiki/Teinte_Saturation_Valeur). Cette représentation est un peu plus représentative de notre perception des couleurs (sans être idéale). On représentera une couleur hsv avec le type:
En vous inspirant des formules données sur la page wikipedia, vous écrirez une fonction tsv ainsi de prototype
La similitude sera définie comme une distance pondérées entre teintes, saturations et valeurs des deux pixels:
Adaptez donc le code précédent de ComposantesConnexesEnCouleurMoyenne pour réaliser cette segmentation. Sur les images papillon-express et kowloon-1000, cela donne les résultats ci-dessous.
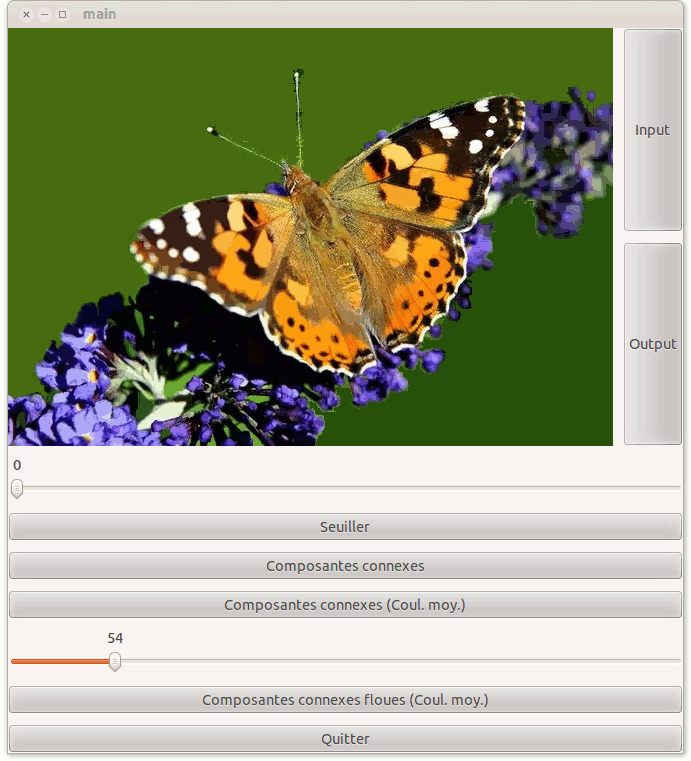
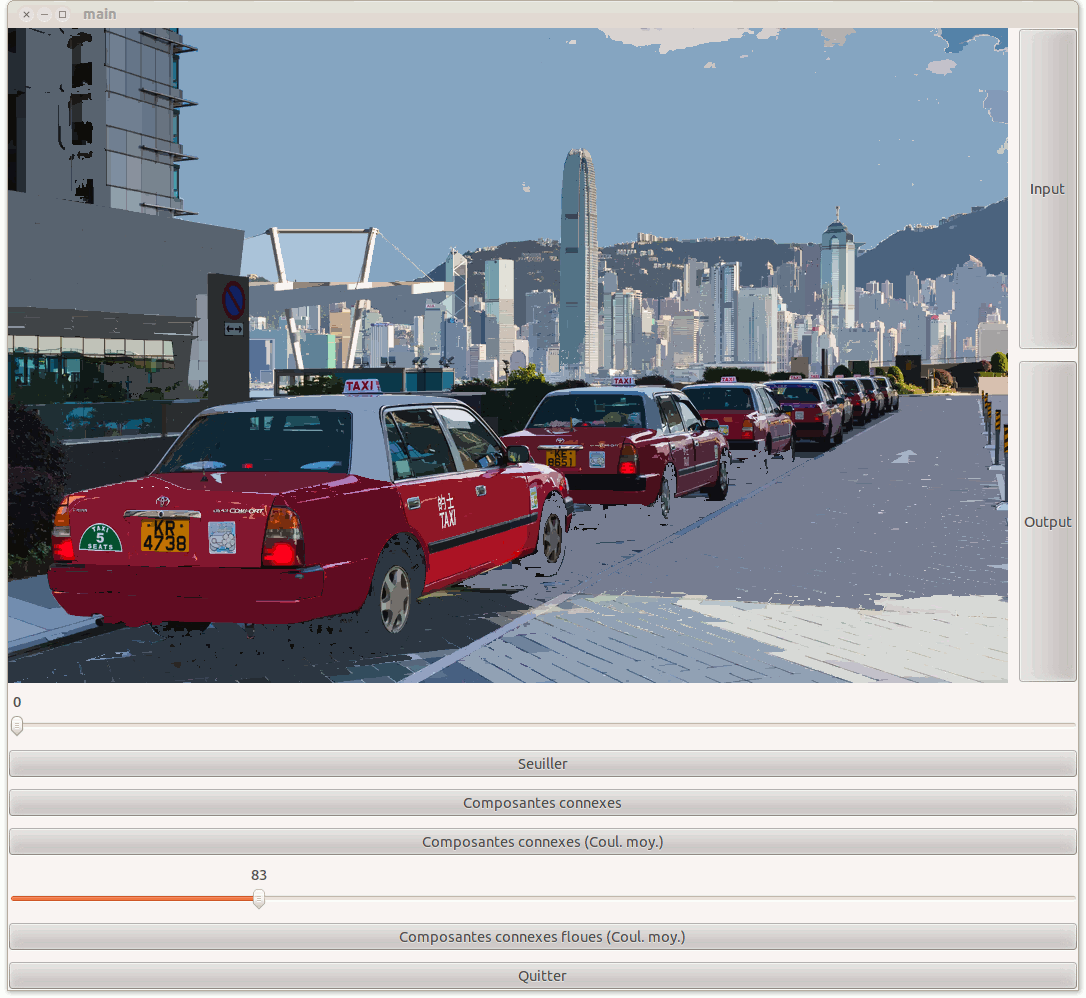
Vous pourrez bien sûr essayer d'autres fonctions similitudes et d'autres images.
- Note
- Faites attention dans les conversions RGB et TSV avec la manipulation des doubles et des entiers en même temps.
6. Remise du tp
- Ce TP peut être fait par binôme.
- vous déposerez votre travail à la fin de la séance via TPLab. Il faudra une archive nommée TP1-[votre ou vos nom(s)] contenant tous les fichiers sources, entêtes, makefile. Vous ajouterez un petit README.txt indiquant les questions traitées complètement et celles traitées partiellement.
- Vous m'enverrez une version finale de votre TP au plus tard dimanche 15 mars minuit via TPLab. Il faudra une archive nommée TP1-[votre ou vos nom(s)] contenant tous les fichiers sources, entêtes, Makefile. Vous me ferez un petit compte-rendu précisant l'état d'avancement (ce qui marche, ce qui marche à moitié, et ce qui ne marche pas), qui donnera un tableau des temps de calcul de Union-Find, et qui pourra montrer quelques exemples de segmentation.
- Vous pouvez éventuellement mettre des exemples de segmentation dans votre compte-rendu, avec d'autres images que celles fournies.
- Bien entendu, il faut que vos programmes compilent sous Linux.